
Experience world-class virtual golf with Golfzon Vision WAVE,
offering realistic 3D courses and global competition on any device.
*Compatible with both WAVE and WAVE Play
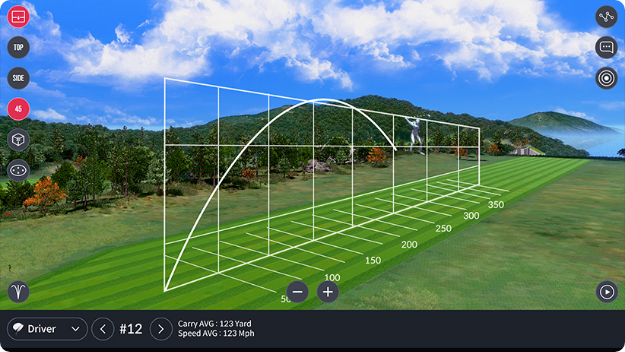
WAVE Skills is a mobile app that displays
detailed shot
data and swing analysis for
Golfzon WAVE users,
enabling
performance
tracking and improvement.
*Exclusive to WAVE
build a large language model from scratch pdf


WAVE Watch app connects to
your WAVE
device via Bluetooth for instant shot results
on your smartwatch, enhancing your golf
experience.
*Compatible with
Apple Watch and Galaxy Watch 4,5
A large language model is a type of


Vision WAVE's mobile version is
set to launch in Q4 2023, offering support for both
iOS and Android devices.
*Compatible with
both WAVE and WAVE Play
Building a large language model from scratch requires


WAVE Arcade is a mobile app that offers
6 innovative arcade games
instead of
traditional 18-hole play.
*Compatible with
both WAVE and WAVE Play
A large language model is a type of neural network that is trained on vast amounts of text data to learn the patterns and structures of language. These models are typically transformer-based architectures that use self-attention mechanisms to weigh the importance of different input elements relative to each other. The goal of a language model is to predict the next word in a sequence of text, given the context of the previous words.
Building a large language model from scratch requires significant expertise, computational resources, and a large dataset. The model architecture, training objectives, and evaluation metrics should be carefully chosen to ensure that the model learns the patterns and structures of language. With the right combination of data, architecture, and training, a large language model can achieve state-of-the-art results in a wide range of NLP tasks.
# Evaluate the model def evaluate(model, device, loader, criterion): model.eval() total_loss = 0 with torch.no_grad(): for batch in loader: input_seq = batch['input'].to(device) output_seq = batch['output'].to(device) output = model(input_seq) loss = criterion(output, output_seq) total_loss += loss.item() return total_loss / len(loader)
# Train the model def train(model, device, loader, optimizer, criterion): model.train() total_loss = 0 for batch in loader: input_seq = batch['input'].to(device) output_seq = batch['output'].to(device) optimizer.zero_grad() output = model(input_seq) loss = criterion(output, output_seq) loss.backward() optimizer.step() total_loss += loss.item() return total_loss / len(loader)
def __len__(self): return len(self.text_data)
def __getitem__(self, idx): text = self.text_data[idx] input_seq = [] output_seq = [] for i in range(len(text) - 1): input_seq.append(self.vocab[text[i]]) output_seq.append(self.vocab[text[i + 1]]) return { 'input': torch.tensor(input_seq), 'output': torch.tensor(output_seq) }
# Define a simple language model class LanguageModel(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim): super(LanguageModel, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True) self.fc = nn.Linear(hidden_dim, output_dim)
